GLM-7B was trained on 1T tokens, of both English, Arabic, and Code, achieving state of the art results across multiple benchmarks and languages.
Generative AI at Enterprises
Over the last year there has been a lot of interest in big Enterprises about using Generative AI to improve operations and product, however, for most Enterprises, the knowledge about how to train such models do not exist within.
Using an AI model using an API is very problematic for many Enterprises who wants to make sure that their proprietary data is never shared with third parties, using a general purpose model that was not trained specifically on your data or language is also not ideal for achieving optimal results. With GLM-7B, you can address both of these concerns.
GLM-7B is designed to meet the privacy requirements of enterprises by offering a self-contained, customizable language model that can be run on-premises or within a secure private cloud managed by the organization. This ensures that all data stays within the organization’s systems, and the model doesn’t share any proprietary information with third parties.
Moreover, GLM-7B is trained on a massive dataset comprising English and Arabic texts, making it a perfect fit for businesses operating in the Middle East, North Africa, or anywhere that may require bilingual language capabilities. It can also be fine-tuned further on your specific data, industry, or use case, providing superior results tailored to your organization’s unique requirements.
Key Features of GLM-7B:
- Multilingual: GLM-7B is a state-of-the-art language model for both Arabic and English, making it highly versatile for a wide range of applications in a bilingual environment.
- Privacy-conscious: The self-contained, modular design of GLM-7B allows it to be deployed within an enterprise’s secure infrastructure, ensuring that data remains private and secure.
- Customizable: GLM-7B can be fine-tuned on your organization’s specific data, domain, or use case, enabling it to better understand and cater to your unique business requirements.
- Cross-domain applications: GLM-7B is suitable for tasks like translation, summarization, content generation, sentiment analysis, customer service, and much more across various industries.
- Tokenization: A new Arabic-English tokenizer has been developed in order to correctly tokenize Arabic text, making inference cheaper and faster.
Process:
Training a large language model on Arabic is not easy, there are a lot of effort to provide enough training data in English online, as open source, however for Arabic, there exists at most 30-40B tokens online. In order to train GLM-7B we had a data split of about 50% Arabic content and 50% English.
In order to be able to train GLM-7B, a huge amount of text had to be scrapped, obtained, filtered, and deduplicated in order to achieve good performance, resulting in the biggest and most diverse dataset of Arabic content ever, covering well over 1 billion pages of Arabic text, as well as multiple humanly translated and verified datasets for additional content.
After training while testing the model we found that the axiom stands, good data in = good results, as such data filtration is a necessary step, for example, we found that ATLAS which is the biggest dataset available in Arabic, is poorly filtered, resulting in sub-par results when filtering all the data using the same method.
In addition to better data, a new tokenizer has been developed to support both English and Arabic, which results in very efficient encoding of text as tokens, compared to GPT3.5 or GPT4, in which each Arabic letter is encoded as a token, making costs about 5x higher, and inference much much slower.
Results
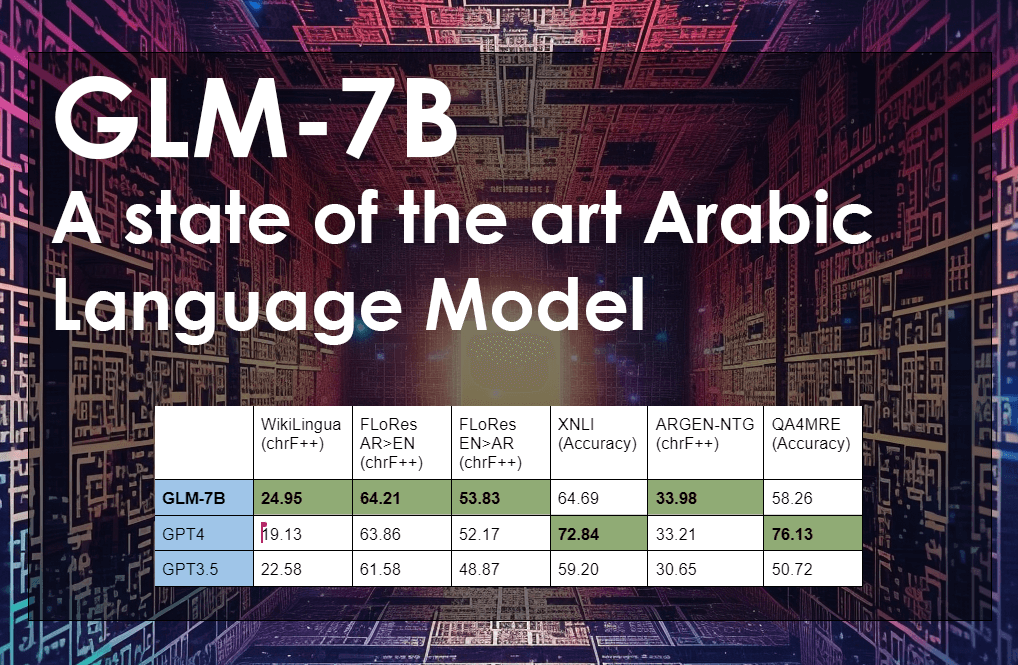
| WikiLingua (chrF++) | FLoRes AR>EN (chrF++) | FLoRes EN>AR (chrF++) | XNLI (Accuracy) | ARGEN-NTG (chrF++) | QA4MRE (Accuracy) | |
|---|---|---|---|---|---|---|
| GLM-7B | 24.95 | 64.21 | 53.83 | 64.69 | 33.98 | 58.26 |
| GPT4 | 19.13 | 63.86 | 52.17 | 72.84 | 33.21 | 76.13 |
| GPT3.5 | 22.58 | 61.58 | 48.87 | 59.20 | 30.65 | 50.72 |
As can be seen, GLM-7B exceeds performance of all other Arabic open source models, as well as GPT3.5 and GPT4 on Arabic benchmarks, achieving state of the art results in most of the benchmarks, making it the first real performant Arabic Language Model.
- WikiLingua: A Multilingual Abstractive Summarization Dataset
WikiLingua, a large-scale, multilingual dataset for the evaluation of cross lingual abstractive summarization systems.
Our model shows 2% better performance on Arabic than even GPT3.5 and GPT4 (surprisingly GPT3.5 is better than GPT4 at summarization), achieving the best performance in Arabic content summarization. - FLoRes: Facebook Low Resource MT Benchmark
FLoRes is a benchmark dataset for machine translation between English and four low resource languages, based on sentences translated from Wikipedia. Our model outperforms both Arabic to English and English to Arabic over GPT 3.5 and GPT4. - XNLI text classification: Cross-lingual Natural Language Inference
The Cross-lingual Natural Language Inference (XNLI) corpus is the extension of the Multi-Genre NLI (MultiNLI) corpus to 15 languages. The dataset was created by manually translating the validation and test sets of MultiNLI into each of those 15 languages. On the Arabic subset of MultiNLI, our model outperforms both GPT 3.5, and is close to GPT4 results. - ARGEN-NTG: Arabic Language Generation Evaluation News Title Generation.
A new benchmark for Arabic language generation and evaluation. We focused on the news title generation task, in which we outperformed both GPT3.5 by about 3% and GPT4 by almost 1%. - QA4MRE: Question Answering for Machine Reading Evaluation
The general goal of the Question Answering for Machine Reading Evaluation (QA4MRE) is to assess the ability of systems in two reading abilities: to answer questions about a text under reading, and to acquire knowledge from reading, especially the knowledge involved in the textual inferences that bridge the gap between texts, questions and answers. In this dataset we perform better than GPT 3.5 by 8%.
Conclusion
GLM-7B is a groundbreaking Arabic-English language model that offers a valuable tool for enterprises seeking to leverage the power of generative AI. Trained on an extensive dataset of over 1T tokens, covering both Arabic and English content, GLM-7B delivers state-of-the-art results across multiple benchmarks and languages.
Key features such as its multilingual capabilities, privacy-conscious design, customization options, and cross-domain applications make it suitable for a wide range of industries, while the novel Arabic-English tokenizer ensures efficient text encoding and inference.
GLM-7B’s exceptional performance on various Arabic benchmarks and tasks, including WikiLingua, FLoRes, XNLI, AraT5, and QA4MRE, demonstrates its potential as a transformative AI solution for organizations operating in bilingual environments. By offering an effective, secure, and customizable language model option, GLM-7B paves the way for robust AI integration within enterprises across the globe.